
Um Netzwerke bilden zu können, ist es erforderlich, einen Adressraum in einzelne Netzwerke einteilen zu können. Dieses Bilden von Unternetzen nennt man "Subnetting".
Warum Subnetting?
Jede Übertragung im Internet basiert auf IP, dem Internet Protocol. Dieses Protokoll definiert unter anderem auch das Adressierungsschema, das auf 4 Bytes große Adressen basiert (siehe hierzu auch IP-Adressierung). Mit dieser Länge der Adresse lassen sich, rein rechnerisch gesehen, rund 4,3 Milliarden unterschiedliche IP-Adressen abbilden.
Dieser Adressraum ist jedoch kaum sinnvoll nutzbar, wenn er nicht systematisch aufgeteilt werden und so entstehende Teilnetze Organisationen zur Verfügung gestellt werden kann. Hier setzt das Subnetting an, das Aufteilen von Netze in Subnetze.
Classful IP Addressing
Bei der Einführung des Internet Protokolls im Jahre 1981 wurde das Classful IP Addressing (Klassifizierte IP-Adressierung) entwickelt. Dieses System teilte den gesamten IP-Adressraum in verschieden große Klassen auf. Ursprünglich waren das drei Klassen: Class A, Class B und Class C. Später kamen noch zwei Klassen namens Class D und Class E hinzu.
Die Zugehörigkeit einer IP-Adresse zu ihrer Klasse wird durch eine logische Aufteilung einer IP-Adresse in zwei Teile geregelt, der Network-Number und der Host-Number. Die Network-Number (auch oft bezeichnet als Network Prefix) definiert die Netzzugehörigkeit, während die Host-Number innerhalb des definierten Netzwerks für die Rechneradressierung zuständig ist. Die Länge der Network-Prefix wird durch die Klassenzugehörigkeit definiert.
- Class A
IP-Adressen aus dem Class A beginnen mit dem Bit 0 und die ersten 8 Bit der IP-Adresse sind die Network Prefix. Rein rechnerisch lassen sich so 128 einzelne Class-A-Netzwerke von 0.x.x.x bis 127.x.x.x mit jeweils 16.777.214 einzelnen IP-Adressen bilden, das erste und das letzte Class-A-Netzwerke sind jedoch für internet-technische Zwecke reserviert (0.0.0.0 wird für die Default-Routen verwendet und 127.0.0.0 für Loopback-Funktionen, also zur Adressierung des eigenen Rechners. - Class B
IP-Adressen aus dem Class B beginnen mit der Bitfolge 1-0 und die ersten 16 Bits der IP-Adresse sind die Network Prefix. Damit lassen sich so 16.384 einzelne Class-B-Netzwerke von 128.0.x.x bis 191.255.x.x mit jeweils 65.534 einzelnen IP-Adressen bilden. - Class C
IP-Adressen aus dem Class C beginnen mit der Bitfolge 1-1-0 und die ersten 24 Bits der IP-Adresse sind die Network Prefix. Damit lassen sich so 2.097.152 einzelne Class-C-Netzwerke von 192.0.0.x bis 223.255.255.x mit jeweils 254 einzelnen IP-Adressen bilden. - Class D
IP-Adressen aus dem Class D beginnen mit der Bitfolge 1-1-1-0 und der Adressbereich liegt zwischen 224.x.x.x und 239.x.x.x. Dieser Adressbereich ist für Multicasting-Anwendungen reserviert. - Class E
IP-Adressen aus dem Class E beginnen mit der Bitfolge 1-1-1-1 und der Adressbereich liegt zwischen 240.x.x.x und 255.x.x.x. Dieser Adressbereich ist für experimentelle und zukünftige Anwendungen reserviert.
Die Entwickler dieses Systems haben in ihrem zweifellos genialen Adressierungsschema allerdings nicht die Erfolgsgeschichte des Internet und den zukünftigen Bedarf an IP-Adressen erahnen können.
So zeigte sich im Laufe der Zeit, dass zwischen den Class-B- und Class-C-Netzen noch eine logische Größe fehlte. Bei größeren Netzwerken mit einem Adressbedarf von 10.000 IP-Adressen war dann die einzig praktikable Schlussfolgerung, solchen Netzwerken ein Class-B-Netz zu vergeben, anstelle von vielen Class-C-Netzen. Dies hatte zur Folge, dass die Zahl der noch verfügbaren Class-B-Netze dramatisch abnahm und deswegen immer stärker Class-C-Netze vergeben wurden. Dies wiederum hatte den Nachteil, dass dadurch die Routing-Tabellen immer komplexer wurden. (Siehe zum Thema Routing auch: Übertragung im Netz - Routing)
Subnetting
Im Jahr 1985 wurde deshalb im RFC 950 das so genannte Subnetting (Aufteilung in Teilnetze) eingeführt. Die Idee bestand hierbei darin, dass zur zweistufigen Hierarchie, bestehend aus Network-Prefix und Host-Number, noch eine dritte Hierarchie eingeführt wurde, die Subnet-Number. Mit dieser Hierarchie konnte ein Netzwerkadministrator ein zugeteiltes Netz innerhalb seiner Organisation in kleinere Netze aufteilen, ohne dass diese Aufteilung im Internet propagiert werden musste. Nach außen in das Internet ist nur das zugeteilte Netz weiterhin nur über die Network-Prefix bekannt.
Präfix
Hostanzahl Subnetzmaske
--------------------------------
/8 16777216 255.0.0.0
/9 128x65536 255.128.0.0
/10 64x65536 255.192.0.0
/11 32x65536 255.224.0.0
/12 16x65536 255.240.0.0
/13 8x65536 255.248.0.0
/14 4x65536 255.252.0.0
/15 2x65536 255.254.0.0
/16 65536 255.255.0.0
/17 128x256 255.255.128.0
/18 64x256 255.255.192.0
/19 32x256 255.255.224.0
/20 16x256 255.255.240.0
/21 8x256 255.255.248.0
/22 4x256 255.255.252.0
/23 2x256 255.255.254.0
/24 256 255.255.255.0
/25 128 255.255.255.128
/26 64 255.255.255.192
/27 32 255.255.255.224
/28 16 255.255.255.240
/29 8 255.255.255.248
/30 4 255.255.255.252
/31 2 255.255.255.254
/32 1 255.255.255.255 |
| Subnetzmasken |
Da beim Subnetting nun zwei Unbekannte existieren (die Subnet- und die Host-Number), muss neben der IP-Adresse noch ein weiteres Kennungsmerkmal vorhanden sein, dass die Größe des Netzwerks kennzeichnet, in der die IP-Adresse organisiert ist. Dazu wurde die Subnetzmaske eingeführt.
Die Subnetzmaske gibt die Länge der so genannten Extended Network Prefix an, dies ist die Bezeichnung für die Network-Prefix und der Subnet-Number. Die Subnetzmaske hat mit 32 Bit genau die gleiche Länge wie eine IP-Adresse und jedes Bit der Subnetzmaske ist genau der Position des jeweiligen Bit in der IP-Adresse zugeordnet. Die Subnetzmaske arbeitet also schablonenartig.
Beispielsweise stellen bei einem Class-C-Netz die letzten acht Bits die Host-Number dar. Demzufolge sind die ersten 24 Bit die Extended Network Prefix. Dies bedeutet für die Subnetzmaske, dass die ersten 24 Bit auf Eins stehen und die letzten 8 auf Null. In der punktiert-dezimalen Schreibweise ergibt dies die Subnetzmaske 255.255.255.0. Eine Übersicht über die möglichen Subnetzmasken finden Sie in nebenstehender Tabelle.
Eine andere Notationsweise ist die Angabe der Präfixlänge zu einer IP-Adresse. Für ein Class-C-Netz wäre die Präfixlänge "/24" und dieses Präfix wird dann an die entsprechende IP-Adresse angehängt. So würde beispielsweise die Angabe "80.245.65.0/24" das Netz von 80.245.65.0 bis 80.245.65.255 beschreiben oder die Angabe von 80.0.0.0/8 das Netz von 80.0.0.0 bis 80.255.255.255. Gelegentlich sieht man auch in dieser Schreibweise, dass nachfolgende Nullen weggelassen werden, so dass anstelle 80.0.0.0/8 einfach 80/8 geschrieben würde. Diese Kurzfassung ist nicht falsch, es sollte jedoch dann unbedingt klargestellt werden, dass es sich um einen IP-Adressbereich handelt, da dies so nicht unbedingt ersichtlich ist.
Eine Besonderheit stellen die Präfixe "/31" und "/32" dar. Während das Präfix "/31" mit theoretisch zwei möglichen IP-Adressen technisch unsinnig ist (beide IP-Adressen würden für die Subnetz- und für die Broadcast-Adresse gebraucht werden, so dass keine mehr übrigbliebe), ist das Präfix "/32" sehr häufig im Einsatz, nämlich in Umgebungen, in denen nur eine IP-Adresse vergeben wird - in Netzwerken, die für Einwahlzugänge genutzt werden. Durch das IP-Adressübersetzungsverfahren NAT (siehe hierzu auch Network Address Translation) ist es in modernen Netzwerken problemlos möglich, dass ein Router nach außen hin nur eine IP-Adresse nutzt, während "hinter" dem Router mit so genannten privaten IP-Adressen das lokale Netzwerk adressiert wird. Der Router fungiert dann als Übersetzer zwischen diesen lokalen Netzwerken und dem Internet.
Die Idee des Subnetting war zwar ein wichtiger Schritt in
die richtige Richtung, dennoch hatte sie eine Schwäche, die
sich im Laufe der Zeit zeigte: Wurde eine Subnetzmaske für
ein Netz festgelegt, so galt sie für das gesamte, zugeteilte
Netz und konnte nicht variabel für einzelne Netzsegmente
angegeben werden. Dieser Umstand war Quelle der nächsten
Entwicklung:
Variable Length Subnet Masks (VLSM)
Im Jahr 1987 wurden im RFC 1009 die Variable Length Subnet Masks (Variabel lange Subnetzmasken) eingeführt. Dieses neue Verfahren behob den Missstand, dass innerhalb eines Netzes nur eine Subnetzmaske verwendet werden konnte und ermöglichte die individuelle Aufteilung von zugeteilten Netzen.
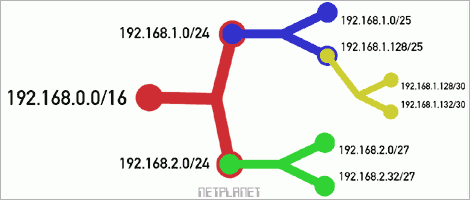
VLSM bezieht sich hierbei wiederum nur auf die organisationsinterne Verwaltung; im globalen Routing spielen diese verfeinerten Subnetzaufteilungen keine Rolle. Umso mehr erleichtert und verbessert VLSM die Nutzung des zugeteilten Adressbereichs innerhalb der Organisation, da Subnetze effizienter gestaltet werden konnten und darüber hinaus Routing-Informationen organisationsintern auf Unternetze delegiert werden konnten. VLSM verbesserte somit die Ausnutzung zugeteilter Subnetze enorm.
Trotz VLSM stieg der Bedarf nach freien IP-Adressen und Subnetzen immer stärker an, nicht zuletzt auch durch den Erfolg des World Wide Web und der aufkommenden Beliebtheit des Internet. Die schlagartig aufkommende Zahl von Webservern und Einwahlzugängen ließen so den Bedarf an IP-Adressen explosionsartig steigen und es wurde befürchtet, dass der gesamte IP-Adressraum schon in wenigen Jahren erschöpft sein könnte. Neben diesem Problem kämpften Provider zusätzlich mit den immer größer werdenden Routing-Tabellen.
Diese Entwicklungen führten dazu, dass 1992 die Teilnehmer der IETF, die Internet Engineering Task Force (siehe hierzu auch Standardisierung im Internet), entsprechende Überlegungen anstellten, wie diese Probleme mittel- und langfristig gelöst werden könnten. Als langfristiges Ziel wurde die Entwicklung eines neuen Internetprotokolls forciert, dem Internet Protocol Version 6 oder kurz: IPv6. Mittelfristiges Ziel war das Überbordwerfen von Altlasten beim aktuellen Internetprotokoll, nämlich den Klassen:
Classless Inter-Domain Routing (CIDR)
Das Classless Inter-Domain Routing ("Klassenloses übergreifendes Routing") wurde im September 1993 in den RFC 1517 bis 1520 dokumentiert. Diese Entwicklung erfolgte dabei in einer wahren Rekordzeit, da allgemein befürchtet wurde, dass die ersten Schwierigkeiten mit dem bisherigen Subnetzsystem bereits 1994 oder 1995 auftreten würden.
CIDR besitzt zwei grundlegende Eigenschaften:
- Das Klassenschema, also einer der Grundpfeiler der ursprünglichen Definition des Internetprotokolls, wurde komplett und ersatzlos über Bord geworfen, so dass nun auch bisherige Class-A-Netzwerke auch innerhalb des Internet und außerhalb von Organisationen in kleinere Subnetze aufteilt werden konnten.
- Das Zusammenfassen von einzelnen Routen zu einem einzigen Routing-Eintrag, um auf diese Weise die globalen Routing-Tabellen grundlegend neu zu strukturieren und zu verkleinern.
Die Abschaffung des Klassenschemas sprengte buchstäblich die Ketten, die die IP-Adressierung bis dato fesselten. Bisher reservierte Class-A-Netzwerke konnten nun von den Regional Internet Registries effizient zur Vergabe von Subnetzen an Provider genutzt werden, die dann diese Subnetze ohne Einschränkungen in verschieden große Subnetze aufteilen konnten. Regional Internet Registries können nun Provider beispielsweise ein /20-Adressblock zuweisen, die diesen Block, je nach Bedarf, frei "portionieren" können. So kann dem Kunden A daraus ein /24-Adressblock, Kunde B ein /29-Block etc. zugewiesen werden, ohne dass es zu Über- oder Unterschneidungen im Adressblock kommt. Die Verwaltung des IP-Adressraums wurde somit für alle Beteiligten erheblich übersichtlicher und transparenter, obwohl nun bei jedem Subnetz die Angabe der entsprechenden Subnetzmaske Pflicht wurde, um so die Größe des jeweiligen Subnetzes definieren zu können.
Die frappierende Ähnlichkeit von CIDR und VLSM ist übrigens nicht zufällig, sondern durchaus eine gewollte Weiterentwicklung einer bewährten Idee. Während die flexiblen Subnetzaufteilungen von VLSM nur innerhalb einer Organisation bekannt waren und das Internet weiterhin nur das gesamte, der Organisation zugeteilte Subnetz kannte, ermöglicht CIDR auch die Bekanntgabe der organisationsinternen Subnetze nach außen zum Internet hin.
Um diese neue Flexibilität nicht mit völlig aus den Fugen geratenden Routing Tabellen zu bezahlen, die so groß sein würden, dass das Internet schlicht nicht mehr funktionieren würde, bezog sich das zweite Konzept von CIDR auf das Zusammenfassen von Routen zu autonomen Netzwerken. Vereinfacht gesagt bedeutet dies, dass Organisationen, die einen IP-Adressblock zugewiesen bekommen haben, diesen autonom verwalten und aufteilen können, nach außen jedoch nur den gesamten IP-Adressblock propagieren.
Vergleichbar ist dies mit der Briefverteilung im herkömmlichen Postverkehr. Wenn Sie beispielsweise einen einfachen Brief an eine Adresse in Pforzheim schicken möchten, schreiben Sie auf den Brief zwar die vollständige Zieladresse, dennoch wird kein Postbediensteter Ihren Brief von Ihrem Ort bis nach Pforzheim tragen. Vielmehr wird Ihr Brief zum Briefverteilzentrum Ihrer Postleitzahlregion geliefert, dort für die Lieferung an die Postleitzahlregion 75 (für Pforzheim) sortiert und gesammelt mit allen anderen Briefen transportiert, die ebenfalls in die Region 75 gehen sollen.
Das Briefverteilzentrum in Pforzheim ist also bundesweit dafür bekannt, dass es die Stelle in Deutschland ist, die autonom Briefe für die Postleitzahlregion 75 verarbeiten kann. Schematisch gesehen "propagiert" also dieses Briefverteilzentrum die gesamte Postleitzahlregion 75 im Briefverkehr der Deutschen Post AG. Niemand (außer dem Briefverteilzentrum Pforzheim natürlich) muss also genau wissen, wie ein Brief in die Bahnhofstrasse nach 75172 Pforzheim transportiert wird. Es genügt, wenn er korrekt adressiert ist und im zuständigen Briefverteilzentrum 75 landet, da man hier genau weiß, wie ein entsprechend adressierter Brief in den Postleitzahlbezirk 75172 und dort in die Bahnhofstrasse transportiert werden muss.
Schematisch ähnlich verläuft das Routing mit dem Routing-Tabellenschema, wie es mit CIDR eingeführt wurde. Der oder die zentrale(n) Router einer Organisation mit einem autonomen IP-Adressblock propagieren ihren gesamten Adressblock im Idealfall mit einem einzigen Routing-Eintrag und geben damit allen anderen zentralen Router aller Organisationen mit eigenen, autonomen IP-Adressblöcken genug Informationen, wohin der Datenverkehr zu einer bestimmten IP-Adresse zur Weitergabe gesendet werden muss.
Reservierte IP-Adressen und Subnetze
Im theoretisch möglichen Adressbereich sind bestimmte IP-Adressen und Subnetze für spezielle Anwendungen gesperrt. Die Kenntnis dieser Ausnahmen ist wichtig, um Falschkonfigurationen und Designfehler zu erkennen und zu vermeiden.
- Erste und letzte IP-Adresse eines Subnetzes
Die erste und die letzte IP-Adresse eines definierten Subnetzes sind jeweils die Subnetz-Adresse beziehungsweise die Broadcast-Adresse. Die Subnetz-Adresse definiert das Subnetz, während die Broadcast-Adresse dazu dient, alle Adressen im Subnetz gleichzeitig ansprechen zu können. - 0.0.0.0/8 (0.0.0.0 bis 0.255.255.255)
IP-Adressen in diesem Bereich dienen als so genannte "Standard-Routen", stehen also für das Subnetz selbst. - 10.0.0.0/8 (10.0.0.0 bis 10.255.255.255)
Dieser komplette /8-Bereich ist reserviert für private Netzwerke. Alle IP-Adressen aus diesem Bereich werden nicht im Internet geroutet und dienen dazu, interne Netzwerke aufzubauen, ohne dafür öffentliche IP-Adressen zu benötigen. - 127.0.0.0/8 (127.0.0.0 bis 127.255.255.255)
IP-Adressen aus diesem Bereich sind reserviert für den so genannten Local Loop. Damit ist für gewöhnlich der eigene Rechner gemeint. Wenn Sie also beispielsweise von Ihrem eigenen Rechner eine IP-Adresse aus diesem Bereich anpingen, bekommen Sie die Antwort von Ihrem eigenen Rechner. - 169.254.0.0/16 (169.254.0.0 bis 169.254.255.255)
IP-Adressen aus diesem Bereich sind reserviert für den so genannten Local Link. Adressen aus diesem Bereich werden genutzt, wenn Rechner in einem gemeinsamen Netz miteinander kommunizieren sollen. Diesen Adressbereich nutzen beispielsweise Rechner, wenn sie eine IP-Adresse automatisch von einem DHCP-Server beziehen sollen, diesen aber nicht finden. - 172.16.0.0/12 (172.16.0.0 bis 172.31.255.255)
Ebenfalls ein Adressbereich, der für die Nutzung in privaten Netzwerken reserviert ist und nicht im Internet geroutet wird. - 192.168.0.0/16 (192.168.0.0 bis 192.168.255.255)
Ebenfalls ein Adressbereich, der für die Nutzung in privaten Netzwerken reserviert ist und nicht im Internet geroutet wird.
IP "reloaded"
Die technische Zukunft des Internet hängt unter anderem auch davon ab, wie lange der Adressbereich noch ökonomisch verwendet werden kann. Inzwischen ist zwar ein akuter Notstand von IP-Adressen mit den derzeitigen Technologien mittelfristig noch nicht (beziehungsweise nicht mehr) zu erwarten, da die kritischsten "Adressverbraucher" mit Weiterentwicklungen unter Kontrolle gebracht wurden. Dazu gehörte die Weiterentwicklung des HTTP-Protokolls, so dass mehrere unabhängige Webserver unter einer einzigen IP-Adresse konfiguriert werden konnten. Eine weitere Erfindung war die Network Address Translation (NAT), die es ermöglicht, lokale Netzwerke mit privaten IP-Adressen zu versehen, so dass hierzu nicht öffentliche IP-Adressen mehr verschwendet werden müssen. Dennoch gibt es auch nach diesen akuten Entschärfungen weiterhin Überlegungen und Visionen, die langfristig einen erheblich größeren Adressraum notwendig machen könnten.
Dazu kommt, dass das Dilemma mit den immer größeren Routing-Tabellen trotz CIDR immer noch besteht. Neben großen Organisationen, die eigene IP-Adressblöcke besitzen und autonom verwalten, benötigen immer mehr auch kleinere Organisationen und Firmen autonome IP-Adressblöcke mit eigenen Routing-Einträgen, da sie beispielsweise aus Sicherheitsgründen über zwei unabhängige Provider redundant am Internet angebunden sein müssen. Dieses "Kleinvieh" von autonomen Mini-Subnetzen bläht die Routing-Tabellen im Internet immer stärker auf. Zwar können diese Wachstume durch den Speicherausbau der einzelnen Router technisch weitgehend aufgefangen werden, dennoch wächst mit den Routing-Tabellen auch der Organisationsaufwand und die Fehleranfälligkeit des Internet gesamt. Deshalb sind neue Ideen und Entwicklungen gefragt, die allesamt in einer Definition eines völlig neuen IP-Adressierungsschemas hinauslaufen werden.
Diese Entwicklungen eines neuen IP-Adressierungsschemas werden von einer Arbeitsgruppe der IETF, der IP Version 6 Working Group, vorangeführt. In dieser Arbeitsgruppe arbeiten Entwickler, Spezialisten und Branchenvertreter zusammen am neuen Internet-Protokoll, das nicht nur ein neues Adressierungsschema haben wird, sondern auch weitere Verbesserungen, die im bisherigen IPv4 noch nicht realisiert sind und auch nicht realisiert werden können.
Weiterführende Links
http://www.3com.com/other/pdfs/infra/corpinfo/en_US/501302.pdf
(PDF)
![]()
Sehr gute Einführung zur IP-Adressierung von Chuck Semeria
http://zeus.fh-brandenburg.de/~ihno/lehre/internet/
Hervorragende
Übersetzung des Dokuments von Ihno Krumreich
http://www.ietf.org/html.charters/ipv6-charter.html
![]()
IP Version 6 Working Group der IETF