
Computer und Kabel machen zwar physikalisch ein Netzwerk aus, funktionieren tut es dennoch noch nicht. Damit Daten von einem Rechner zum anderen übertragen werden können, ist es notwendig, dass jemand diesen Rechnern sagt, wo eigentlich die anderen Rechner in diesem Netzwerk zu finden sind. Dies geschieht durch Routing.
Was ist Routing?
Das Substantiv "Routing" bedeutet in der deutschen Sprache so viel wie "Reiseroute" oder "Routenplanung" und hat sich in der Netzwerksprache als "denglischer" Begriff durchgesetzt. Der Begriff umschreibt die Mechanismen, die notwendig sind, um in einem Netzwerk einheitliche Datenübertragungsrouten zu definieren, auf denen Daten am effizientesten übertragen werden können. (Wird Routing als Verb benötigt, wird übrigens von "routen" gesprochen.)
Routing dient in einem Netzwerk dazu, logische Übertragungswege zu definieren, auf denen Daten von einem Punkt zum anderen übertragen werden können. Ich will das an einem kleinen schematischen Beispiel darstellen:
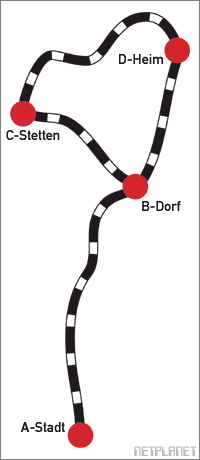 Rechts
sehen Sie ein kleines Bahnnetz, das vier Städte
miteinander verbindet. Die gesamten Gleisstücke zwischen den
Städten sind miteinander physikalisch verbunden (es wäre
auch relativ unpraktisch für eine Eisenbahn, wenn sie das
nicht täten..).
Rechts
sehen Sie ein kleines Bahnnetz, das vier Städte
miteinander verbindet. Die gesamten Gleisstücke zwischen den
Städten sind miteinander physikalisch verbunden (es wäre
auch relativ unpraktisch für eine Eisenbahn, wenn sie das
nicht täten..).
Grundsätzlich sind die Planer von Zügen, die dieses kleine Gleisnetz benutzen sollen, bestrebt, Züge möglichst schnell von einem Punkt zum anderen fahren zu lassen, um das Streckennetz möglichst wenig zu belasten und die Züge effizient zu nutzen. Soll also beispielsweise ein Zug von A-Stadt nach D-Heim fahren, würde dieser Zug folgendermaßen fahren:
Von A-Stadt über B-Dorf nach D-Heim.
Der Zug könnte theoretisch auch über B-Dorf und C-Stetten fahren, dies würde jedoch die Fahrstrecke und damit auch die Fahrzeit verlängern, wäre also nicht effizient gegenüber der obigen Streckenführung. Gleichwohl könnte dieser Umweg aber als "Havariestrecke" vorgesehen sein, wenn beispielsweise das Gleisstück zwischen B-Dorf und D-Heim vorübergehend gesperrt würde. Die Planung von solchen Routen, also das Bilden von logischen Streckenführungen auf einem physikalischen Streckennetz, bezeichnet man als Routing.
Wir können mit unserem kleinen, fiktiven Bahnnetz noch einen Schritt weiter gehen und für jeden Standort eine Tabelle erstellen, aus der ersichtlich ist, wie am besten alle anderen Standorte erreicht werden können. Für D-Heim würde das so aussehen:
Von D-Heim nach A-Stadt: Südliche Gleisstrecke über
B-Dorf nach A-Stadt.
Von D-Heim nach B-Dorf: Direkt über südliche Gleisstrecke
nach B-Dorf.
Von D-Heim nach C-Stetten: Direkt über nördliche
Gleisstrecke nach C-Stetten.
So eine Tabelle (die in ähnlicher Form, natürlich in viel
größeren Maßstäben, tatsächlich von "echten" Eisenbahnen
für Zugplanungen verwendet werden) ist eine klassische
Routing-Tabelle. Wir werden später noch sehen, dass
der Vergleich zwischen so einem Bahnnetz und dem Routing im
Internet durchaus nicht hinkt.
Routing in Netzwerken und im Internet
Vom Prinzip her hat ein Bahnnetz sehr viel mit einem Computernetzwerk zu tun. Beide bestehen aus einem Streckennetz, das möglichst effizient genutzt werden muss, damit sich seine Vorteile möglichst schnell bezahlt machen. Ein Netzwerk allein bringt also erst einmal gar nichts, mindestens genauso wichtig wie die physikalische Infrastruktur ist die Logik der Datenübertragung. Sprich: Das beste Bahnnetz nützt nichts, wenn niemand weiß, wie die angeschlossenen Orte am effizientesten erreicht werden können.
Wenn Sie sich einmal anschauen, welche Daten Sie von Ihrem Internet Provider bekommen, wenn Sie eine Verbindung in das Internet haben, werden Sie einige interessante Daten sehen. Beispielsweise könnte diese Konfiguration, die Sie bei jedem Internet-Zugang haben, folgendermaßen aussehen:
IP-Adresse
: 192.168.0.10
Subnetzmaske : 255.255.255.0
Standard-Gateway : 192.168.0.1
Was genau besagen nun diese Daten?
Bei der IP-Adresse und der Subnetzmaske ist der Fall weitgehend klar: Die angegebene IP-Adresse ist die IP-Adresse des Rechners, unter die er erreichbar ist. Die Subnetzmaske definiert die Netzgröße des Netzes, aus dem die IP-Adresse stammt. In diesem Fall besitzt der Rechner also die IP-Adresse 192.168.0.10 aus dem Netz, welches von 192.168.0.0 bis 192.168.0.255 reicht (näheres zur IP-Adressierung finden Sie im Artikel: IP-Adressierung). Damit können Sie auf jeden Fall schon mal Rechner erreichen, die innerhalb von 192.168.0.0 und 192.168.0.255 liegen, doch haben Sie noch keinen wirklichen, direkten Internet-Zugang, denn wie kommen Daten außerhalb dieses Netzes?
Dazu dient das so genannte Standard-Gateway, oft auch als Default-Gateway bezeichnet. Das Standard-Gateway ist praktisch der "Standardausgang" für alle Daten, die an Zieladressen außerhalb des eigenen Netzes adressiert sind, das ja mit IP-Adresse und Subnetzmaske genau definiert ist. Dieses Standard-Gateway ist der so genannte Router, der den Übergang in andere Netze vornimmt, deshalb mindestens zu zwei Netzen Zugang besitzt. (Der Begriff "Router" ist hierbei erst einmal nicht als Hardware-Gerät zu verstehen, denn auch normale Computer mit Netzwerkanschluss können als Router arbeiten.)
Eine einfache Routing-Tabelle für unseren fiktiven Rechner würde demnach so aussehen:
Netzwerkziel
Netzwerkmaske Gateway
Metrik
0.0.0.0
0.0.0.0
192.168.0.1 100
127.0.0.0
255.0.0.0
127.0.0.1 1
192.168.0.0 255.255.255.0
192.168.0.10 100
192.168.0.10 255.255.255.255
127.0.0.1 100
Das Lesen dieser kleinen Routing-Tabelle ist recht einfach: Das Netzwerkziel steht für das Zielnetzwerk, die Netzwerkmaske definiert die Größe dieses Zielnetzwerks und das Gateway steht für die Adresse des Rechners, über die das Zielnetzwerk zu erreichen ist. Die Metrik ist ein Wert zur Steuerung der Priorität eines Routing-Eintrags, je niedriger, desto höher in der Priorität. Mit der Metrik ist es beispielsweise möglich, mehrfache Routen für gleiche Netzwerkziele zu planen.
Im Einzelnen liest sich die Routing-Tabelle, die übrigens in der Regel numerisch sortiert ist, wie folgt:
- Das Netzwerk 0.0.0.0 mit der Subnetzmaske 0.0.0.0 steht bezeichnend für den gesamten IP-Adressraum, also quasi für alle IP-Adressen im Internet. Das Gateway, das für das Netzwerkziel 0.0.0.0/0.0.0.0 zuständig ist, ist für gewöhnlich das Standard-Gateway. Für dieses Netzwerk ist deshalb in unserem Beispiel das Gateway die 192.168.0.1, da dies auch das Standard-Gateway ist.
- Das Netzwerk 127.0.0.0/8 ist ein im Internet reservierter IP-Adressbereich (siehe auch IP-Subnetting), der immer für den lokalen Rechner reserviert ist. Erkennbar ist das auch daran, dass als Gateway für dieses Netzwerkziel die 127.0.0.1 angegeben ist, also unser Rechner selbst.
- Das Netzwerk 192.168.0.0/255.255.255.0 ist das Netzwerk, aus dem die IP-Adresse unseres Rechners stammt. Da wir zum Erreichen von Zieladressen deshalb kein Standard-Gateway benötigen, ist für dieses Netzwerkziel unser Rechner selbst das Gateway, also die 192.168.0.10.
- Mit dem Netzwerkziel 192.168.0.10/255.255.255.255 (mit dieser Subnetzmaske ist also nur die einzelne IP-Adresse 192.168.0.10 als Ziel gemeint) ist schließlich unser Rechner selbst gemeint, es wird hier deshalb als Gateway auf die 127.0.0.1 geroutet.
Grundlegend ist das auch schon alles, was den "Mythos Routing" ausmacht. Freilich sind die meisten Routing-Tabellen, die Ihnen über den Weg laufen werden, weit komplexer und schwieriger zu lesen, dennoch geht es bei Routing grundsätzlich immer nur darum, Verknüpfungen zwischen zwei oder mehreren Netzen zu schaffen. Sich immer diesen Umstand im Geiste aufzurufen, hilft auch beim Lesen und Verstehen der komplexesten Routing-Tabellen.
Manuelles Routen und dynamisches Routen mit Routing-Protokollen
Manuell erstellte Routing-Tabellen haben jedoch zwei große Nachteile: Sie können bei vielen zu berücksichtigen Routen schnell sehr unübersichtlich werden und in Umgebungen, in denen sich schnell Routen ändern können, unflexibel, weil für jede Änderung Hand angelegt werden muss.
In den Frühzeiten des ARPANet, dem militärischen Vorläufer des Internet, war das Problem der immer stärker ausufernden Routing-Tabellen schon nach wenigen Jahren zu spüren. Bei jedem Rechner, der neu in das ARPANet aufgenommen wurde, mussten die Betreiber aller bereits angeschlossenen Rechner ihre Routing-Tabellen manuell ergänzen, damit dieser neue Rechner auch von ihnen aus erreichbar war. Dies war auch notwendig, wenn ein Rechner im ARPANet eine andere Route bekam und Sie können sich unschwer ausmalen, wie häufig alle Routing-Tabellen geändert werden mussten und wie dementsprechend schlecht das Administrationspersonal auf irgendwelche angekündigten Netzwerkänderungen anzusprechen war.
Die immer stärkere Notwendigkeit für Automatismen beim Erstellen und Pflegen von Routing-Tabellen wurde auch dann immer brennender, als im Jahre 1983 vom Netzwerkprotokoll NTP mit seinen maximal 256 möglichen Rechneradressen auf das neue Protokoll TCP/IP (siehe hierzu auch TCP/IP - Haussprache des Internet) umgestellt wurde, mit dem theoretisch über 4 Milliarden Rechner direkt adressiert werden konnten. Unmöglich waren hier Routing-Tabellen von Hand zu pflegen, die Angaben für beispielsweise tausende Netzwerke beinhalten sollten.
Manuelles Routing verliert deshalb immer mehr da an Stellenwert, wo es viele einzelne Netze gibt, für die entsprechende Routing-Einträge vorhanden sein müssen. Bei einem Router, der beispielsweise hinter einem privaten Netzwerk und nur ein einziges Netzwerk in das Internet routen muss, mag der Aufwand noch überschaubar sein (es müssen ja dort letztendlich "nur" zwei Netzwerke miteinander verbunden werden, das lokale Netzwerk und das Internet). Sprechen wir aber über Router, die beispielsweise Unternehmensnetzwerke mit dem Internet verbinden oder direkt in Internet-Backbones bei Netzbetreibern im Einsatz kommen, ist hier das Routing keinesfalls mehr von Hand zu machen. Für solche Szenarien gibt es dynamisches Routing anhand Routing-Protokollen, mit denen ein automatischer Aufbau von Routing-Tabellen möglich ist.
Um fundamentale Missverständnisse zu vermeiden: Der letzte Satz ist genau so zu verstehen, wie er geschrieben ist: Routing-Protokolle übernehmen nicht das Routing selbst, sondern übernehmen lediglich den Part, der ansonsten manuell erledigt werden müsste: Den Aufbau von Routing-Tabellen.
Routing-Algorithmen im dynamischen Routing
Bei Routing-Algorithmen wird zwischen zwei verschiedenen Ansätzen unterschieden:
- Distance Vector nach Bellmann-Ford-Algorithmus
("Teile deinen Nachbarn mit, wie die Welt aussieht")
Der Distance-Vector-Algorithmus arbeitet "extrovertiert"; jeder Router führt eine Routing-Tabelle, in die er ihm alle bekannten Netze einträgt. Diese Routing-Tabelle wird regelmäßig zwischen den Routern per Broadcast vollständig ausgetauscht, was gerade bei größeren Netzen in relativ kurzer Zeit sehr große Übertragungsmengen sein können. Ein weiterer gefürchteter Nachteil sind Inkonsistenzen in Routing-Tabellen, wenn bei teilweisen Netzwerkstörungen die Routing-Tabellen einzelner Router durch andere Router überschrieben werden, die die Störungen noch nicht erkannt haben. Durch einige Erweiterungen (Reverse Poison, Split Horizon, Hold-down) werden die größten Nachteile zwar teilweise gelindert, dennoch ist der Distance-Vector-Algorithmus trotz seiner anfänglichen Einfachheit mit Vorsicht zu genießen, vor allem in großen, weit verzweigten und relativ störungsanfälligen Netzwerken. - Link State nach Dijkstra-Algorithmus ("Teile
der Welt mit, wer deine Nachbarn sind")
Der Link-State-Algorithmus arbeitet gewissermaßen "introvertiert". Auch hier führt jeder Router eine eigene Routing-Tabelle, in der die gesamte Topologie des Netzwerks abgebildet ist. Änderungen in einer Verbindung werden jedoch als so genanntes Link State Announcement den benachbarten Routern mitgeteilt, die diese Information wiederum an ihre Nachbarn weitergehen und so weiter. Da mit diesem Algorithmus eventuelle Routing-Tabellenänderungen sehr moderat und zielgerichtet weitergegeben werden, eignet er sich für sehr große Netzwerke und Routing-Tabellen.
Feinjustage Metrik
Die Metrik ist eine wichtige "Regelschraube" im Routing und insbesondere in Routing-Tabellen, die automatisch erstellt werden, da mit der Metrik eine Wertigkeit ins Spiel gebracht werden kann. Ein Netzwerkziel kann so beispielsweise mehrfach in einer Routing-Tabelle auftauchen und mit einem Wert für die Metrik kann die Bevorzugung angegeben werden. Hat eine bestimmte Route für ein Netzwerkziel eine niedrigere Metrik, so wird diese gegenüber einer Route für dasselbe Netzwerkziel bevorzugt.
Die Metrik kommt vor allem dann zum Zuge, wenn in einem Routing-Szenario auch Alternativrouten berücksichtigt werden müssen, die beispielsweise dann nahtlos zum Einsatz kommen sollen, wenn die bevorzugte Route ausfällt, zum Beispiel durch eine Leitungsunterbrechung. Solche Ausfälle können zwar auch durch Routing-Protokolle analysiert und in Routing-Tabellen berücksichtigt werden, alternative "Havarierouten" sind im Ernstfall aber erheblich schneller aktiv, praktisch innerhalb weniger Sekunden.
Verschiedene Routing-Protokolle
Routing-Protokolle unterscheiden sich nicht nur durch den verwendeten Routing-Algorithmus, sondern auch für ihren primären Verwendungszweck. Grundsätzlich wird beim Routing zwischen zwei Zielgruppen unterschieden: Den Netzwerken innerhalb eines lokalen Netzwerks oder autonomen Systemen und den autonomen Systemen im Internet untereinander. Alle Routing-Protokolle lassen sich in jeweils eine solche Gruppe einordnen; der Gruppe der Interior Gateway Protocols und der Gruppe der Exterior Gateway Protocols.
Interior Gateway Protocols (IGP)
Innerhalb eines lokalen Netzwerks oder einem autonomen System sind vor allem Routing-Protokolle gefragt, die auf die unterschiedlichsten Netzwerkstrukturen vorbereitet sind. In solchen Netzwerken finden sich häufig unterschiedliche Übertragungsgeschwindigkeiten; lokale Netzwerke mit sehr hohen Bandbreiten, DSL-Zugänge mit mittelmäßigen und vielleicht ISDN-Standleitungen mit sehr geringen Bandbreiten. Zudem arbeiten vielleicht nicht alle Segmente so eines Netzwerkes wirklich hundertprozentig zuverlässig und genau solchen "Schmutz" muss ein IGP-Protokoll auffangen können, ohne dass das restliche Netzwerk unkontrollierbar wird.
Geläufige IGP-Vertreter sind beispielsweise das Routing Information Protocol (RIP) und das komplexe Open Shortest Path First (OSPF):
- Routing Information Protocol (RIP)
RIP arbeitet mit dem Distance-Vector-Algorithmus und eignet sich für kleinere Netze, in denen sich die Netzwerkstruktur nur selten ändert. Da RIP sehr gesprächig sein kann, gibt es bei häufigen Strukturänderungen regelmäßig sehr viele Routing-Änderungen, die die Router ständig versuchen, miteinander auszutauschen. Da das Routing sich ständig ändern und nicht konsistent bleibt, spricht man hier von "flappenden Routen". - Open Shortest Path First (OSPF)
OSPF arbeitet mit dem Link-State-Algorithmus und eignet sich auch für größere Netze, in denen sich die Netzwerkstruktur häufiger ändert. Nachteilig äußert sich bei OSPF der erheblich komplexere Aufbau des Protokolls und der nicht zu unterschätzende Konfigurationsaufwand.
Exterior Gateway Protocols (EGP)
Für die Steuerung des Routing im Internet, also zwischen autonomen Systemen, gelten zwar letztendlich die gleichen technischen Grundlagen des Routing, jedoch auf einer völlig anderen Ebene, da die Regel gilt: Je kleiner die Routing-Tabelle, desto besser. Dies wird deutlich, wenn Sie sich vor Augen halten, dass im Internet über 145.000 Routen (Stand: September 2004) propagiert werden müssen, für jedes autonome System ein einzelner Routing-Eintrag. Tendenz steigend.
Allerdings sind Routing-Änderungen auf dieser Ebene eher überschaubar. Da buchstäblich nicht jede defekte Netzwerkverbindung in einem autonomen System den Datenverkehr des Internet sonderlich stört, beschränkt sich das Routing im Internet auf das wirklich Grundsätzliche, dementsprechend finden hier vergleichbar wenig Änderungen weltweit statt.
- Border Gateway Protocol (BGP)
BGP4 (die Zahl 4 steht hierbei für die Version 4) arbeitet mit dem Distance-Vector-Algorithmus und eignet sich für sehr große Netze mit autonomen Systemen (eben unter anderem auch für das Internet), auf deren Ebene nur geringe Änderungen stattfinden, sowohl technisch, als auch administrativ.
Verbindungstypen
Wir sind jetzt bisher immer davon ausgegangen, dass eine Datenübertragung zwei Punkte besitzt, also eine Ende-zu-Ende-Verbindung. Diese Art der Datenübertragung wird in der Netzwerktechnik als Unicast bezeichnet. Daneben gibt es jedoch noch zwei weitere Verbindungstypen, die nicht unerwähnt sein sollten und ich hier deshalb eine Definition liefern möchte:
- Unicast ("Ende-zu-Ende")
Unicast-Verbindungen gehen von einem Ende zu einem anderen. Häufig wird auch von "Punkt-zu-Punkt" gesprochen, dies ist jedoch nur dann richtig, wenn zwischen diesen Punkten keine weiteren Zwischenstationen befinden, sie also direkt miteinander verbunden sind. Da im Internet jedoch in der Regel keine Übertragung ohne Zwischenstationen erfolgt, sind echte Punkt-zu-Punkt-Verbindungen im Internet nicht zu finden. - Broadcast ("Ende-zu-Teilnetz")
Broadcast-Verbindungen gehen von einem Ende zu allen Rechnern des Teilnetzes, in dem sich der absendende Rechner befindet. Dieser Verbindungstyp ist beispielsweise dann notwendig, wenn ein Rechner per Broadcast-Anfrage in einem Teilnetz alle Rechner kontaktiert, um auf diese Weise kennen zu lernen, welche Rechner noch im Teilnetz vorhanden sind. Das Protokoll DHCP arbeitet ebenfalls mit Broadcast-Anfragen; der Rechner schickt hierzu eine Broadcast-Anfrage an alle Rechner im Teilnetz, die dann von einem DHCP-Server beantwortet wird. - Multicast ("Ende-zu-Gruppe")
Multicast-Verbindungen sind ebenfalls ein Verbindungstyp, bei dem die Daten eines Rechners an mehrere Rechner gleichzeitig übertragen werden. Im Gegensatz zu Broadcast müssen diese Rechner jedoch nicht in einem, sondern können auch in unterschiedlichen Teilnetzen liegen. Damit so eine netzwerkübergreifende Multicast-Übertragung funktioniert, wird in der Regel mit einem virtuellen Netz, das über ein logisches Netzwerk die empfangenden Rechner miteinander verbindet. Zu diesem Zweck ist im IP-Adressraum der Adressbereich von 224.0.0.0 bis 239.0.0.0 (auch als "Class D" bezeichnet, siehe IP-Subnetting) für Multicast-Anwendungen reserviert. - Anycast ("Ende-zu-Nächst-Ende")
Anycast ist ein relativ junger Verbindungstyp, der in den letzten Jahren vor allem bei globalen Diensten wie den Root Servern im Domain Name System (siehe auch Domain Name System) Einzug gefunden hat. Bei Anycast ist eine ganze Gruppe von Rechnern unter einer einzelnen IP-Adresse erreichbar und bei einer Anfrage an diese IP-Adresse wird diese an den Rechner geleitet, der über die kürzeste Route erreicht werden kann. Damit dies funktionieren kann, werden Routing-Protokolle eingesetzt, in denen die einzelnen Rechner in einem Anycast-Verbund jeweils unterschiedliche Gewichtungen haben, je nachdem, aus welchem Netz die IP-Adresse angesprochen wird.
Wird das Internet einmal "unroutbar"?
Immer wieder werden Bedenken geäußert, dass das Internet irgendwann einmal unsteuerbar werden könnte, da die globalen Routing-Tabellen unaufhörlich größer werden. Nun, die letztere Feststellung ist zumindest nicht falsch, es gibt tatsächlich im Internet immer mehr autonome Systeme. Die Zahl wächst weniger durch immer neue Netzbetreiber oder Internet Provider, sondern eher durch den Drang vieler Unternehmen, ihre Netzwerke nicht nur über einen Internet Provider an das Internet anzubinden, sondern über mehrere unabhängige. Die Grundvoraussetzung für so eine Redundanz ist nämlich ein autonomes System.
Eine einfache Antwort: Eine höhere Zahl von Routing-Einträgen ist eine Frage der Leistungsfähigkeit der Router. Gerade hier haben die wichtigsten Router-Hersteller in den letzten Jahren enorme Entwicklungsschübe hinter sich, so dass auch das weitere Anwachsen der globalen Routing-Tabellen in den nächsten Jahren keine größeren Probleme darstellen sollten. Darüber hinaus arbeitet BGP4 ebenfalls hierarchisch und ermöglicht es kleineren Netzbetreibern, nicht alle Routing-Einträge aller autonomen Systeme wissen zu müssen, sondern diese Angaben Fall zu Fall von einem BGP4-fähigen Router eines angebundenen Netzbetreibers zu ermitteln.
Dennoch gehen die Entwicklungen für zukünftige Routing-Protokolle für das Internet weiter, es ist jedoch nicht zu erwarten, dass demnächst das Internet unsteuerbar wird.